osdev-jpでは、OS開発に有用な情報を収集し公開しています
OpeLa コンパイラのレジスタ割り当てアルゴリズムの説明です。
レジスタ割り当て
メモリよりレジスタの方が格段に読み書きが高速なため、如何に多くの変数や値をレジスタに保存できるかが性能向上のために重要です。 レジスタは本数がとても少ないため、どの変数や値をレジスタに割り当てる(assign)かを決めるアルゴリズムを上手く設計する必要があります。
一般のレジスタ割り当て問題は NP 完全であるとされていて、大きなプログラムに対して最適なレジスタ割り当てを求めるのは困難です。 「コンパイラ―原理・技法・ツール」 では現実的な時間でレジスタ割り当て問題を解くためのヒューリスティックな手法が紹介されています。
式と文
本題に入る前に、簡単に「式」と「文」を説明します。
式は結果となる値が返ってくるもののことです。例えば加算式 1+2 や関数呼び出し式 f(a, b) などがあります。これらは、結果として何らかの値を表します。
(例外として関数の戻り値が void だと値を返しませんが、それでも関数呼び出し式に分類されます。)
一方で文は値を返しません。if 文や for 文などは代表的な文です。また、C 言語では行末にセミコロンを書きますが、あれは「式文」という文の書き方です。
c = f(a, b); // 式文。「代入式」+「;」の形。
if (c) { puts("c is true"); } // if 文。文全体としては値を返さない。
C 言語では if は文で、値を返しません。しかし、if が式であるような言語もあり、その場合は if の結果を変数に代入したりできます。
d = if (c) { 42 } else { 0 };
c が真のとき、変数 d に 42 が書き込まれます。if 式が値を返しているわけですね。
(C 言語ではこの用途で 3 項演算子「?:」が使われます。)
式に対するレジスタ割り当て
OpeLa コンパイラ Ver.2 は途中式の値をレジスタに格納して計算します。例えば 1+2 をコンパイルすると次のようなアセンブリコードを出力します。
mov eax, 1
mov edi, 2
add rax, rdi
RAX レジスタに 1 を、RDI レジスタに 2 を格納し、最後に ADD 命令を使って RAX に RDI を足し込みます。これで希望する値を計算できますね。 この処理の中で、レジスタ割り当てとは 1 を RAX に、2 を RDI に置くこと、さらに RAX+RDI の結果を RAX に置くことを決める処理ですね。
OpeLa コンパイラ Ver.2 では、式を対象に、レジスタが最小になるレジスタ割り当てアルゴリズムを採用します。
Ershov 数
レジスタが最小になる割り当てには Ershov 数というものを用います。Ershov(エルショフ)は人の名前です。これから説明するアルゴリズムは 「コンパイラ―原理・技法・ツール」 の 「8.10 Optimal Co de Generation for Expressions」で説明されています。
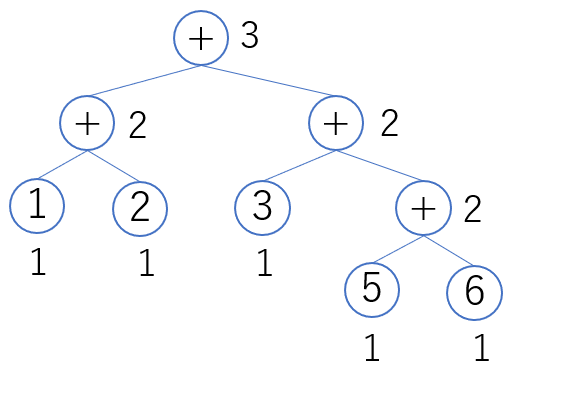
Ershov 数は次の手順で構文木の各ノードに付与していきます。
- すべての葉のラベルを「1」とする
- 1 つの子だけ持つ中間ノードのラベルは、子と同じ数値とする
- 2 つの子を持つ中間ノードのラベルは
- 子の数値が異なる→大きい方と同じ数値
- 子の数値が等しい→それより 1 大きい数値
例えば (1+2) + (3+(5+6)) という式に対する Ershov 数は次のようになります。
Ershov 数を用いたレジスタ割り当て
準備として、計算に使うレジスタに通し番号を振ります。ここで R[0]、R[1]、…… とします。 実際のレジスタ名は R[0]=RAX、R[1]=RDI、という感じになります。
コード生成は構文木のルートから開始し、再帰的に実行します。 複数の子を持つノードの場合、大きな Ershov 数を持つ子から先に評価する、というのが全体の方針です。
ラベル k を持つ中間ノードのコード生成は、ベース値 b から連続する k 個のレジスタを使います。 つまり R[b]、R[b+1]、……、R[b+k-1] のレジスタを使うということです。 ノードの評価結果は R[b+k-1] に格納されます。
2 つの子のラベルが等しい場合
評価対象ノードのラベルを k とすると、子のラベルは k - 1 となります。これは Ershov 数の付与ルールから導かれます。
2 つの子のラベルが等しいので、どちらの子を先に評価しても差はありませんが、 教科書では右辺を先に評価するということにしているようです。
- ベース値 b+1 を使い、右辺のコードを再帰的に生成する
- ベース値 b を使い、左辺のコードを再帰的に生成する
- R[b+k-2]、R[b+k-1] を使って演算し、結果を R[b+k-1] に書く
レジスタの使われ方を下図に示します。青い背景のレジスタがそのノードの計算に使用されます。太枠で囲んだレジスタに、そのノードの計算結果が書かれます。
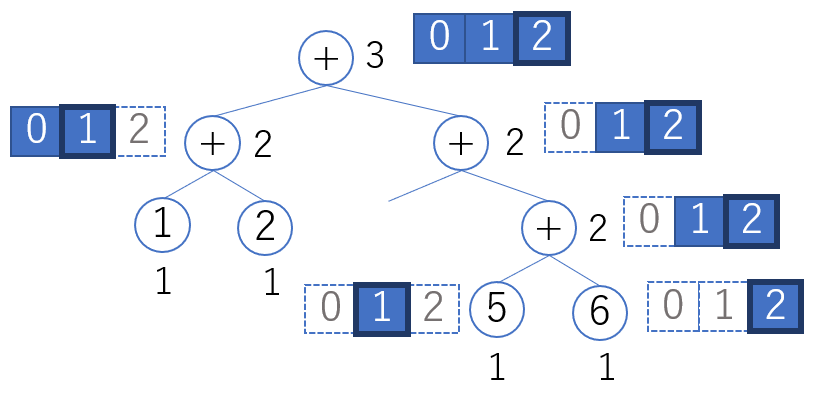
ルートノードから見て右側の木を先に評価します。 右側の木のラベルは 2 なので、評価するには 2 つのレジスタが必要だということが分かります。 右側の木はベース値 b+1(この例では 1)で評価しますから、R[1]、R[2] が使われます。 結果は R[b+k-1] = R[2] に書かれます。
次にルートノードの左側の木を評価します。 左側の木のラベルも 2 なので、評価するには 2 つのレジスタが必要です。 ベース値 b(この例では 0)で評価するため、R[0]、R[1] が使われます。 結果は R[b+k-2] = R[1] に書かれます。 左側の木を評価する過程で、絶対に R[2](右側の木の評価結果が書かれているレジスタ)を上書きしないのがミソです。
2 つの子のラベルが異なる場合
評価対象ノードのラベルを k とすると、大きい方の子のラベルは k、小さい方の子のラベルは m < k となります。これは Ershov 数の付与ルールから導かれます。
先に大きい方の子を評価します。
- ベース値 b を使い、大きい方の子のコードを再帰的に生成する
- ベース値 b を使い、小さい方の子のコードを再帰的に生成する
- R[b+m-1]、R[b+k-1] を使って演算し、結果を R[b+k-1] に書く
レジスタの使われ方を下図に示します。
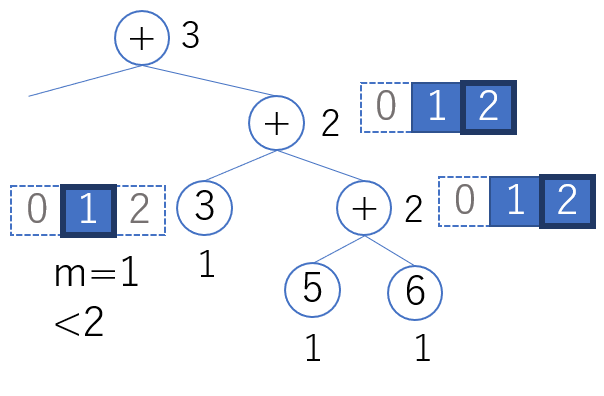
大きい方の子の評価結果は R[b+k-1] に書かれます。 小さい方の子のラベル m は必ず k より小さいため、小さい方の子の評価過程で R[b+k-1] を上書きすることはありません。
コード生成の実例
Ershov 数を用いたコード生成を実装した OpeLa コンパイラで (1 + 2) + ((3 + 4) + (5 + 6)) をコンパイルしてみると次のようなコードが生成されました。
mov eax,3
mov edi,4
add rax,rdi
mov edi,5
mov esi,6
add rdi,rsi
add rax,rdi
mov edi,1
mov esi,2
add rdi,rsi
add rax,rdi
最小のレジスタ数で演算ができていることが分かります。
必要なレジスタ数の上限
2 項演算からなる式の計算に必要なレジスタ数は、高々構文木の高さとなります。
(1 + 2) + ((3 + 4) + (5 + 6)) は高さ 4 の木ですが、必要なレジスタ数は 3 個です。
大抵の式は木の高さより少ないレジスタで計算可能です。
必要なレジスタ数と構文木の高さが等しい例としては、1+2(木の高さは 2)や (1+2)+(3+4)(木の高さは 3)などがあります。
左右にバランス良く成長した木の方が、(木の高さの割に)必要レジス多数が多くなりやすいです。
OpeLa 言語は SystemV AMD64 ABI にしたがった機械語を出力しますので、気軽に計算に使えるレジスタは RAX、RDI、RSI、RDX、RCX、R8、R9、R10、R11 の 9 個となります。 したがって、高さ 9 の木まではレジスタが足りなくなることはありません。
レジスタを 9 個消費する高さ 9 の木とは、例えばこんな式です: (((((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))+(((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))))+((((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))+(((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))))+(((((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))+(((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))))+((((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))+(((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1))))+((((1+1)+(1+1))+((1+1)+(1+1)))+(((1+1)+(1+1))+((1+1)+(1+1)))))))
普通、こんな長大な式は書かないでしょうから、式のコンパイルにおけるレジスタ不足は考えないことにします。
一般のコンパイラ最適化では複数の文にまたがったレジスタ割り当てを考えます。 そうすると途端にレジスタが不足します。 レジスタが不足した場合、レジスタスピル(register spill)という、レジスタの値をメモリに退避させる処理が必要になります。 とりあえずは単一式のみでレジスタ割り当てを行うことで、最適化を妥協します。
レジスタ割付けとレジスタ割当て
レジスタ割付け(Register allocation)とレジスタ割当て(Register assignment)は似ていますが、コンパイラの分野では明確に使い分けられているようです。
-
レジスタ割付け: どの変数をレジスタに置くかを決める処理のこと。具体的なレジスタ名までは決めない。
-
レジスタ割当て: レジスタに置くと決めたそれぞれの値をどのレジスタに置くかを決める処理のこと。
-
参考
- コンパイラ ―原理・技法・ツール― 第2版 「レジスタの割付けと割当て」
- "11.6.1 Register Allocation vs. Assignment" https://web.cs.wpi.edu/~cs544/PLT11.6.1.html